딥 러닝의 구현에 있어 모델은 오차율에 대한 지표를 통해 딥 러닝 모델이 스스로의 정확도를 판단하고 그 오차율을 줄이는(곧 정답률을 늘리는) 방향으로 내부 파라미터를 수정하는 방식으로 학습이 이루어진다.
즉, 모델에게는 '학습' 자체를 가능하도록 하는 지표로서의 오차 값을 계산할 함수가 필요하다.
이러한 지표의 역할을 하는 함수들을 통칭 비용 함수 또는 손실 함수(Cost function / Loss function)이라 한다.
손실 함수에는 대표적으로 MSE(Mean Squared Error), CEE(Cross Entropy Error)가 있으며, 딥 러닝 방법론을 제시하는 논문들에서 RMSE(Rooted Mean Squared Error), MAE(Mean Absolute Error) 등을 모델 성능 비교 지표로 활용하기도 한다.
이후 경사 하강법과 역전파법을 다루는 글에서 자세히 설명하겠지만, 자동 학습을 위해서는 손실 함수의 미분 가능성이 중요한 특성이 된다.
왜냐하면, 딥 러닝 모델은 파라미터(ex - W)의 변화율에 따른 손실 함수(L(y))의 값 변화율, 즉 dL(y)/dW를 지표로 파라미터를 수정하기 때문이다.
손실 함수에 미분 불가능한 지점, 또는 기울기가 0이 되는 지점이 존재한다면(그리고 그 지점이 학습 과정에서 마주치게 될 가능성이 크다면), 학습을 통한 모델의 개선은 그 원리에 따라 크게 저해받게 되는 것이다. 이는 딥 러닝에서의 활성화 함수에 있어서도 중요한 특성이 된다.
이제 수식과 함께 손실 함수들의 특성에 대해 알아보자.


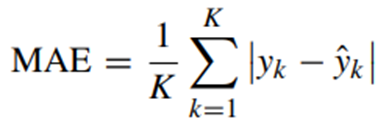
MAE 수식은 위와 같다.
오차치에 절댓값을 취하여 평균을 구하는 방식으로 계산한다. 특징으로는 절댓값만을 취하므로 제곱에 비해 오차치에 robust하다는 점이 있다. 단점으로 보일 수 있겠으나 모델이 특정 데이터에만 최적화되어 범용성이 적어지는 경우(Overfitting)을 막을 수 있다고 한다. 또한 오차치의 영향이 적은 전반적인 모델 성능지표로 활용할 수 있다.
한 편 MAE는 대부분의 지점에서 미분이 가능하나 딱 한 군데, 0인 지점에서는 뾰족한 개형이라 미분이 불가능하나, 사실 경사하강법의 목적이 손실 함수가 최소인 지점(0)을 찾는 것이 목적이므로 손실 함수로 사용하는 데에는 무리가 없을 것 같다.

RMSE 수식은 위와 같다.
MSE를 구하고 제곱근을 취하여 계산하는데, 이 계산 과정 때문에 역시 1보다 큰 오차치에는 더 큰 오차 계수를 반환하지만, 제곱근에 의해 그 가중치는 MSE보다 작다.
이러한 특성은 오차치에 MAE보다는 민감하고, MSE보다는 robust한 것으로 설명할 수 있으며, 이들의 특성을 고려하여 적절한 성능 지표로 활용하는 것이 바람직하겠다.
MAE와 마찬가지로 0인 지점에서만 미분 불가능하다.
Reference
언제 MSE, MAE, RMSE를 사용하는가?
제목에 열거한 RMSE, MSE, MAE는 딥러닝 모델을 최적화 하는 데 가장 인기있게 사용되는 오차 함수들이다. 이번 포스팅에서는 (1) 이들의 특징을 알아보고, (2) 이 3 가지 손실 함수를 비교 분석해본다
jysden.medium.com
[2] https://gooopy.tistory.com/63
딥러닝-5.3. 손실함수(4)-교차 엔트로피 오차(CEE)
지난 포스트까지 제곱오차(SE)에서 파생된 "오차제곱합(SEE), 평균제곱오차(MSE), 평균제곱근오차(RMSE)"에 대하여 알아보았다. 해당 개념들이 연속형 데이터를 대상으로 하는 회귀분석의 모델 적합
gooopy.tistory.com
'Machine Learning > Deep Neural Network' 카테고리의 다른 글
| [StackExchange 펌] CNN 오버피팅 방지와 배치 사이즈 (0) | 2023.02.28 |
|---|---|
| [DL] Activation functions Insight ~ Swish와 Mish (0) | 2023.01.13 |
| [DL] Activation Functions Insight ~ Sigmoid, tanh, ReLU (0) | 2023.01.02 |

